
コンテンツ生成AIによる不正学習・データの無断利用に対しての批判は、開発企業の急速なAI普及戦略のもとで、無効化・透明化されていると感じているクリエイターも多いでしょう。一方で、不正学習・データの無断利用に対しての技術開発も着実に進化してきています。
また、大手メディアやエンターテイメント企業などをはじめとして、法的な措置に乗り出すコンテンツ提供者が増えてきています。こうした一連の動きの中で、インターネット上にあるデータ収集そのものを改革しようといった動向も出てきています。そうした考えを支える技術として「Pay Per Crawl」という課金システムが注目されています。
この「Pay Per Crawl」は、生成AIによる不正利用に苦しむクリエイターにとって、新たな救済策となり得る可能性を秘めています。そこで、今回は「Pay Per Crawl」の基礎知識や、それによってもたらされるメリット・デメリットなどをクリエイター視点で詳しく解説します。
目次
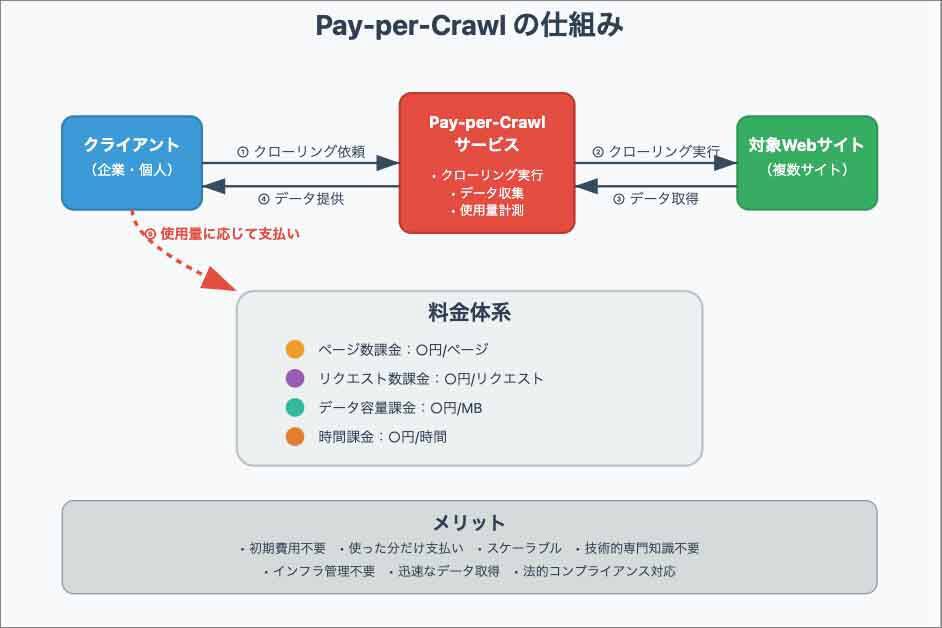 Pay-per-Crawlの課金イメージ(図解はClaudeで作成)インターネット上のデータ取得は、検索クローラーというWebサイトを巡回しデータを収集する仕組みによって成り立っています。Googleをはじめとした検索エンジンは、このクローラーを使い膨大な情報を集めてきました。この「検索のためのクローリング」は、ユーザーに直接課金されることなく、誰もが無料で検索結果を享受できる仕組みを支えています。
Pay-per-Crawlの課金イメージ(図解はClaudeで作成)インターネット上のデータ取得は、検索クローラーというWebサイトを巡回しデータを収集する仕組みによって成り立っています。Googleをはじめとした検索エンジンは、このクローラーを使い膨大な情報を集めてきました。この「検索のためのクローリング」は、ユーザーに直接課金されることなく、誰もが無料で検索結果を享受できる仕組みを支えています。
一方で、主に企業や開発者向けに提供されている、特定の目的(市場調査やデータ収集など)のための「クローリングサービス」が存在します。これらのサービスは、データ収集機能そのものをビジネスとして有償で提供しており、従来の料金体系は月額固定制やクローリング量に応じた従量課金が一般的でした。
「Pay Per Crawl(略してPPC)」は、その名の通り「クロールした分だけ課金される」新しい仕組みです。このモデルは、必要な範囲に限定してデータを収集できる柔軟性から注目を集めています。
▶Pay Per Crawlが注目される背景
 CloudflareのPay Per Crawlに関するページPay Per Crawlが大きな注目を集めているのは、Cloudflare社が提唱した新しい考え方が、現在のインターネットのあり方に一石を投じたと大きく報じられているからです。
CloudflareのPay Per Crawlに関するページPay Per Crawlが大きな注目を集めているのは、Cloudflare社が提唱した新しい考え方が、現在のインターネットのあり方に一石を投じたと大きく報じられているからです。
生成AIや機械学習の急速な普及に伴い、「特定のデータを効率的に取得したい」というニーズが急増しました。しかし、無制限のクローリングはWebサイトに大きな負荷を与えるため、運営者との間で摩擦が生じていました。これは、AI開発企業がWeb上のコンテンツを無断で学習していることへの反発や批判と相まって、大きな社会問題となっています。
こうした「検索のためなら無償クローリングが当然」という従来の考え方をそのまま受け入れる状況に対し、異議を唱える形で2025年7月に発表されたのがCloudflareが提唱するPay Per Crawlサービスなのです。「クロールした分だけ課金する」という考え方自体は、データ収集業界では以前から存在していました。しかし、Cloudflareが革新的なのは、このモデルをWebの基盤にまで広げようとしている点にあります。
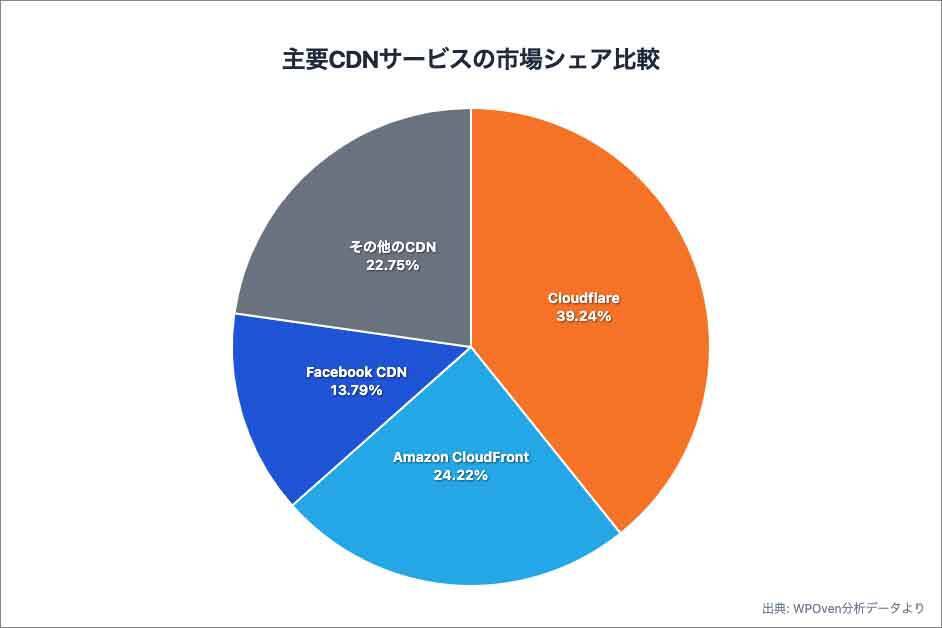 主要CDNサービスの市場シェア比較(出典:WPoven分析データ/グラフはデータを参照しClaudeで作成)Cloudflareは、Webトラフィックの大部分を処理するコンテンツ配信ネットワーク(CDN)において、39.24%という市場シェアを誇る企業です(出典:WPOven)。さらに、DDoS攻撃保護といったセキュリティ基盤も提供しており、Webセキュリティとインフラ開発のトップ企業としての地位を確立しています。
主要CDNサービスの市場シェア比較(出典:WPoven分析データ/グラフはデータを参照しClaudeで作成)Cloudflareは、Webトラフィックの大部分を処理するコンテンツ配信ネットワーク(CDN)において、39.24%という市場シェアを誇る企業です(出典:WPOven)。さらに、DDoS攻撃保護といったセキュリティ基盤も提供しており、Webセキュリティとインフラ開発のトップ企業としての地位を確立しています。
こうした強大な影響力は、検索エンジン企業に匹敵するとされており、Googleのような巨大テック企業に対しても対抗し得る存在として、この新しい提唱に大きな注目が集まっているのです。
※参照記事:Cloudflare Market Share [Statistics & Report](WPOven)
Pay Per Crawlが普及することでクリエイターにとってのメリットは、Web上に公開した自身の作品が生成AIに無断で利用される状況に対して、収益を発生させる一つの対抗手段となり得る点です。これまで、ブログ記事やポートフォリオに掲載した作品がAIの学習データとして利用されても、クリエイターには何の見返りもありませんでした。しかし、Pay Per Crawlの仕組みが導入されれば、AI開発企業は対象サイトをクロールするごとに利用料を支払うことになります。
無断学習されること自体、許すべきではないという考えるクリエイターが多いと思いますが、今行われている無断学習に対して現実的な対策となりうる技術の一つであるという点は注目すべきポイントでしょう。
▶作品の価値を守る
生成AIによる無断学習はクリエイターにとって深刻な問題ですが、完全に防ぐことが難しい現実もあります。その中でPay Per Crawlは、AI企業が作品を取得する際に「正規のライセンス料」を支払う仕組みとして解釈できる点に意義があります。それが作品の価値をどこまで正当に評価することにつながるかは未知数です。しかし、少なくとも「無断利用を前提とするのではなく、提供者に還元する仕組みを持つ」という方向性は、現行の問題を是正する重要な一歩となるでしょう。
▶情報アクセスの透明性
Pay Per Crawlの導入は「どのAIがどのデータを利用しているか」という透明性を高める可能性があります。課金の仕組みを通じて利用履歴や支払い経路が記録されるため、作品の利用状況を把握しやすくなるのです。自分の作品がどの生成AI企業に利用されたのかを確認できれば、単なる収益化にとどまらず、無断学習を差し止めたいクリエイターにとって法的措置を取るための根拠としても活用できるでしょう。
▶広告収入に依存しないことで得られる自由な表現
フジテレビ問題など、本年冒頭から続くマスメディアの不祥事やコンプライアンス違反の背景には、広告スポンサーや大手芸能事務所への過度な忖度が大きな影を落としていました。健全な情報社会を考えると、こうした状況は望ましくありません。
Pay Per Crawlによる収益モデルが定着すれば、クリエイターは広告主の意向やトレンドに縛られることなく、自由で独自性の高い表現が可能となります。もちろん、広告収入がメディア運営や高品質なコンテンツ制作を支えているという重要な側面は今後も変わらないでしょう。しかし、「広告に依存しない表現の場」をWebメディアにも広げられることは、創作環境の多様性と健全性を強化する大きな一歩といえます。
Pay Per Crawlは、クロールごとの課金ですので、1回あたりの課金額に換算すると非常に少額の料金になります。つまり、膨大なアクセス量があることが前提となって、はじめて現実的な収益を確保できるのです。これは、アクセス数の少ない個人ブログやポートフォリオサイトで作品を発表している事業者は、恩恵を受けにくいことも意味します。そのため、小規模な事業者は収益を得るための手段としてPay Per Crawlを活用することは難しいといったデメリットがあると考えられます。
▶利用の不均衡
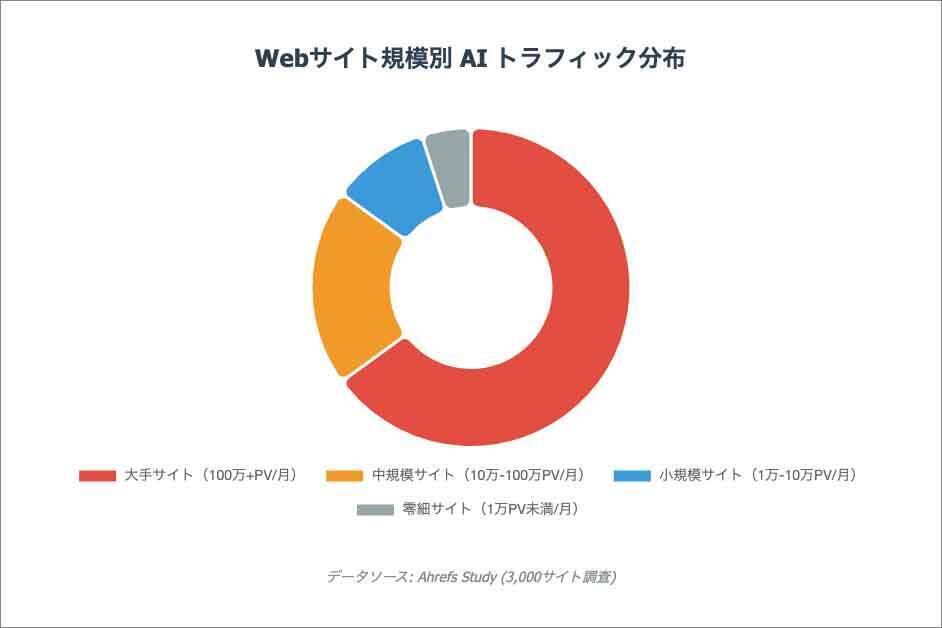 Webサイト規模別AIトラフィック分布(出典:Ahrefs/グラフはClaudeで作成)Pay Per Crawlの課金モデルは理論上すべての情報提供者に利益をもたらしますが、現実には大手メディアや有名プラットフォームに収益が集中する可能性が高いといえます。また、AI開発企業も効率的な学習のために、アクセス数の多い大手サイトや、広範囲にわたる情報を扱うプラットフォームを優先的にクロールする傾向があります。そのため利用の不均衡が生じ、コンテンツの多様性を損なうリスクにつながりかねません。こうした傾向を強化することは、情報生態系全体にとって望ましくない状況を生む懸念があります。
Webサイト規模別AIトラフィック分布(出典:Ahrefs/グラフはClaudeで作成)Pay Per Crawlの課金モデルは理論上すべての情報提供者に利益をもたらしますが、現実には大手メディアや有名プラットフォームに収益が集中する可能性が高いといえます。また、AI開発企業も効率的な学習のために、アクセス数の多い大手サイトや、広範囲にわたる情報を扱うプラットフォームを優先的にクロールする傾向があります。そのため利用の不均衡が生じ、コンテンツの多様性を損なうリスクにつながりかねません。こうした傾向を強化することは、情報生態系全体にとって望ましくない状況を生む懸念があります。
※参照記事:63% of Websites Receive AI Traffic (New Study of 3,000 Sites)(Ahrefs)
▶技術的ハードル
Pay Per Crawlを導入するには、対象サイト側で設定や契約が必要になる場合があります。そのため、すべてのWebサイトがすぐに利用できるわけではなく、特に技術的な知識やサーバー管理の経験が乏しいクリエイターにとっては導入のハードルが高いと考えられます。こうしたハードルがあることで、結果的に大手企業やプラットフォームが先行して取り入れ、個人クリエイターや小規模サイトは置き去りにされる構図が再生産される可能性も否定できません。
▶情報格差の拡大
資金力のあるAI開発企業がデータ取得の対価を支払うことを重視すれば、有料で情報を提供する大手メディアの情報がAIの学習の大部分を占めることになります。その結果、小規模な事業者やクリエイターのユニークな作品は、ニッチな情報としてAIに十分に活用されず、コンテンツの多様性が失われる恐れがあります。
こうした情報提供者(メディアやクリエイター)の格差拡大と同様に、情報を利用する側のユーザーにも格差が生じる恐れがあります。AIや検索の質が「Pay Per Crawlに対して十分な課金をできる企業」に有利になるからです。もし有料の情報が優先的に取得されるようになれば、資金力のない個人や小規模事業者は、高品質な情報を活用しづらくなり、結果として得られる情報の質や精度に差が出る可能性があります。
Pay Per Crawlの普及によって、Webコンテンツが今のように無料でアクセスできなくなる可能性は低いと考えられますが、このような格差が生じることは、情報の公平性を損なう深刻な課題となるでしょう。
Pay Per Crawl以外にも、AIクローラーをデフォルトでブロックする仕組みの導入など、Cloudflareがクローリング業界の新たな基準を作ろうと、その動きを活発化させていることも見逃せません。こうした動向がクリエイターを含む情報提供者やコンテンツ提供者に支持されれば、ダイナミック課金(データ量だけでなく、コンテンツの質や人気に応じて料金が変動する課金方法)のような柔軟な料金モデルへと進化し、中小サイトへの普及によって持続可能な収益構造が形成される可能性もあるでしょう。
さらに、法的な整備や標準化が進むことで、この新しいモデルの信頼性と公平性が高まるかもしれません。「アクセス許可と対価」という新しい関係が台頭していくことで、これまで難しいとされてきた生成AI開発企業とのコンテンツ利用契約が、現実味を帯びてくるかもしれません。
※参照記事:Cloudflare to Block AI Crawlers by Default, Let Sites Demand Payment(Business Insider)
※参照記事:Block Or Charge AI Bots Accessing Your Website(Tech Insight)
※参照記事:Cloudflare will now block AI crawlers by default(The Verge)
こうした状況の中で、テキスト領域においても無断学習に対抗する動きが活発になっています。
また、日本でも日本経済新聞、朝日新聞がPerplexity AIに対して著作権侵害で共同提訴し、読売新聞も同様の訴訟を行ったといった報道がなされています。さらに、著作権者である作家3人がClaudeを開発するAnthropic社を提訴していたAI無断学習訴訟では、先日和解が成立したことも報じられています。これらの動きは、クリエイターの権利保護に向けた法廷闘争が現実的な成果を生み出し始めていることを示しています。
これらの動向は、GoogleやMicrosoft、OpenAIといった巨大テック企業ではなく、PerplexityやAnthropicのような新興AI企業を対象に訴訟が起こされるケースが多い傾向があるのは気になりますが、おそらく訴訟しやすい部分からの取り組みだと考えられ、今後巨大テック企業も視野に入れた法廷闘争へ発展していく可能性もあると予測されます。
※参照記事:日経・朝日、米AI検索パープレキシティを提訴 著作権侵害で(日本経済新聞)
※参照記事:読売新聞社、「記事無断利用」生成AI企業を提訴…日本の大手報道機関で初(読売新聞)
※参照記事:AI無断学習訴訟で和解 米アンソロピックと作家ら(時事通信ドットコム)
このような変化の中で、コンテンツの価値を正当に評価するPay Per Crawlが支持される土壌は確実に生まれつつあります。そして、Pay Per Crawlは、テキストだけでなく、画像、映像、音楽など、あらゆるコンテンツ分野において、生成AIの無断学習に対抗する技術の一つになり得ることも、クリエイターにとっては大きな希望になるでしょう。
こうした技術が普及するか否かは、私たちは見守ることしかできませんが、クリエイターの方々がPay Per Crawlという技術を正しく理解することは、その普及を後押しする大きな力となるでしょう。本記事が、その理解の一助になれば幸いです。

また、大手メディアやエンターテイメント企業などをはじめとして、法的な措置に乗り出すコンテンツ提供者が増えてきています。こうした一連の動きの中で、インターネット上にあるデータ収集そのものを改革しようといった動向も出てきています。そうした考えを支える技術として「Pay Per Crawl」という課金システムが注目されています。
この「Pay Per Crawl」は、生成AIによる不正利用に苦しむクリエイターにとって、新たな救済策となり得る可能性を秘めています。そこで、今回は「Pay Per Crawl」の基礎知識や、それによってもたらされるメリット・デメリットなどをクリエイター視点で詳しく解説します。
目次
「Pay Per Crawl」とは何か?
▶Pay Per Crawlという技術の基礎知識
一方で、主に企業や開発者向けに提供されている、特定の目的(市場調査やデータ収集など)のための「クローリングサービス」が存在します。これらのサービスは、データ収集機能そのものをビジネスとして有償で提供しており、従来の料金体系は月額固定制やクローリング量に応じた従量課金が一般的でした。
「Pay Per Crawl(略してPPC)」は、その名の通り「クロールした分だけ課金される」新しい仕組みです。このモデルは、必要な範囲に限定してデータを収集できる柔軟性から注目を集めています。
▶Pay Per Crawlが注目される背景

生成AIや機械学習の急速な普及に伴い、「特定のデータを効率的に取得したい」というニーズが急増しました。しかし、無制限のクローリングはWebサイトに大きな負荷を与えるため、運営者との間で摩擦が生じていました。これは、AI開発企業がWeb上のコンテンツを無断で学習していることへの反発や批判と相まって、大きな社会問題となっています。
こうした「検索のためなら無償クローリングが当然」という従来の考え方をそのまま受け入れる状況に対し、異議を唱える形で2025年7月に発表されたのがCloudflareが提唱するPay Per Crawlサービスなのです。「クロールした分だけ課金する」という考え方自体は、データ収集業界では以前から存在していました。しかし、Cloudflareが革新的なのは、このモデルをWebの基盤にまで広げようとしている点にあります。

こうした強大な影響力は、検索エンジン企業に匹敵するとされており、Googleのような巨大テック企業に対しても対抗し得る存在として、この新しい提唱に大きな注目が集まっているのです。
※参照記事:Cloudflare Market Share [Statistics & Report](WPOven)
Pay Per Crawlがクリエイターにもたらすメリット
▶収益化の新しい形Pay Per Crawlが普及することでクリエイターにとってのメリットは、Web上に公開した自身の作品が生成AIに無断で利用される状況に対して、収益を発生させる一つの対抗手段となり得る点です。これまで、ブログ記事やポートフォリオに掲載した作品がAIの学習データとして利用されても、クリエイターには何の見返りもありませんでした。しかし、Pay Per Crawlの仕組みが導入されれば、AI開発企業は対象サイトをクロールするごとに利用料を支払うことになります。
無断学習されること自体、許すべきではないという考えるクリエイターが多いと思いますが、今行われている無断学習に対して現実的な対策となりうる技術の一つであるという点は注目すべきポイントでしょう。
▶作品の価値を守る
生成AIによる無断学習はクリエイターにとって深刻な問題ですが、完全に防ぐことが難しい現実もあります。その中でPay Per Crawlは、AI企業が作品を取得する際に「正規のライセンス料」を支払う仕組みとして解釈できる点に意義があります。それが作品の価値をどこまで正当に評価することにつながるかは未知数です。しかし、少なくとも「無断利用を前提とするのではなく、提供者に還元する仕組みを持つ」という方向性は、現行の問題を是正する重要な一歩となるでしょう。
▶情報アクセスの透明性
Pay Per Crawlの導入は「どのAIがどのデータを利用しているか」という透明性を高める可能性があります。課金の仕組みを通じて利用履歴や支払い経路が記録されるため、作品の利用状況を把握しやすくなるのです。自分の作品がどの生成AI企業に利用されたのかを確認できれば、単なる収益化にとどまらず、無断学習を差し止めたいクリエイターにとって法的措置を取るための根拠としても活用できるでしょう。
▶広告収入に依存しないことで得られる自由な表現
フジテレビ問題など、本年冒頭から続くマスメディアの不祥事やコンプライアンス違反の背景には、広告スポンサーや大手芸能事務所への過度な忖度が大きな影を落としていました。健全な情報社会を考えると、こうした状況は望ましくありません。
Pay Per Crawlによる収益モデルが定着すれば、クリエイターは広告主の意向やトレンドに縛られることなく、自由で独自性の高い表現が可能となります。もちろん、広告収入がメディア運営や高品質なコンテンツ制作を支えているという重要な側面は今後も変わらないでしょう。しかし、「広告に依存しない表現の場」をWebメディアにも広げられることは、創作環境の多様性と健全性を強化する大きな一歩といえます。
Pay Per Crawlがもたらす影響と懸念点
▶小規模な事業者への影響Pay Per Crawlは、クロールごとの課金ですので、1回あたりの課金額に換算すると非常に少額の料金になります。つまり、膨大なアクセス量があることが前提となって、はじめて現実的な収益を確保できるのです。これは、アクセス数の少ない個人ブログやポートフォリオサイトで作品を発表している事業者は、恩恵を受けにくいことも意味します。そのため、小規模な事業者は収益を得るための手段としてPay Per Crawlを活用することは難しいといったデメリットがあると考えられます。
▶利用の不均衡

※参照記事:63% of Websites Receive AI Traffic (New Study of 3,000 Sites)(Ahrefs)
▶技術的ハードル
Pay Per Crawlを導入するには、対象サイト側で設定や契約が必要になる場合があります。そのため、すべてのWebサイトがすぐに利用できるわけではなく、特に技術的な知識やサーバー管理の経験が乏しいクリエイターにとっては導入のハードルが高いと考えられます。こうしたハードルがあることで、結果的に大手企業やプラットフォームが先行して取り入れ、個人クリエイターや小規模サイトは置き去りにされる構図が再生産される可能性も否定できません。
▶情報格差の拡大
資金力のあるAI開発企業がデータ取得の対価を支払うことを重視すれば、有料で情報を提供する大手メディアの情報がAIの学習の大部分を占めることになります。その結果、小規模な事業者やクリエイターのユニークな作品は、ニッチな情報としてAIに十分に活用されず、コンテンツの多様性が失われる恐れがあります。
こうした情報提供者(メディアやクリエイター)の格差拡大と同様に、情報を利用する側のユーザーにも格差が生じる恐れがあります。AIや検索の質が「Pay Per Crawlに対して十分な課金をできる企業」に有利になるからです。もし有料の情報が優先的に取得されるようになれば、資金力のない個人や小規模事業者は、高品質な情報を活用しづらくなり、結果として得られる情報の質や精度に差が出る可能性があります。
Pay Per Crawlの普及によって、Webコンテンツが今のように無料でアクセスできなくなる可能性は低いと考えられますが、このような格差が生じることは、情報の公平性を損なう深刻な課題となるでしょう。
Pay Per Crawlに関する注目の動向
Cloudflareによる「Pay Per Crawl」サービスが正式に発表されて以降、「The Atlantic」「TIME」「BuzzFeed」といった欧米の大手メディアが、すでにAI企業との間でアクセスに応じた有料契約を結んでいることが報道されました。Pay Per Crawl以外にも、AIクローラーをデフォルトでブロックする仕組みの導入など、Cloudflareがクローリング業界の新たな基準を作ろうと、その動きを活発化させていることも見逃せません。こうした動向がクリエイターを含む情報提供者やコンテンツ提供者に支持されれば、ダイナミック課金(データ量だけでなく、コンテンツの質や人気に応じて料金が変動する課金方法)のような柔軟な料金モデルへと進化し、中小サイトへの普及によって持続可能な収益構造が形成される可能性もあるでしょう。
さらに、法的な整備や標準化が進むことで、この新しいモデルの信頼性と公平性が高まるかもしれません。「アクセス許可と対価」という新しい関係が台頭していくことで、これまで難しいとされてきた生成AI開発企業とのコンテンツ利用契約が、現実味を帯びてくるかもしれません。
※参照記事:Cloudflare to Block AI Crawlers by Default, Let Sites Demand Payment(Business Insider)
※参照記事:Block Or Charge AI Bots Accessing Your Website(Tech Insight)
※参照記事:Cloudflare will now block AI crawlers by default(The Verge)
まとめ
生成AIによる無断学習に対し、多くのクリエイターが批判的な立場から対抗策を模索しています。ただ、画像生成AIが大きな議論を呼んだ一方で、新聞社や出版社、作家、ライターといったテキストコンテンツの提供者は、先行する大規模言語モデル(LLM)の急速な普及に対応することが難しく、取り残されている状態にありました。しかし、テキスト分野でも無断学習の問題がクリエイターに不利益をもたらすことに変わりはありません。こうした状況の中で、テキスト領域においても無断学習に対抗する動きが活発になっています。
実際に、米国では「The Wall Street Journal」や「New York Post」を傘下に持つDow JonesおよびNews CorpがAI企業Perplexity AIを提訴しています。
また、日本でも日本経済新聞、朝日新聞がPerplexity AIに対して著作権侵害で共同提訴し、読売新聞も同様の訴訟を行ったといった報道がなされています。さらに、著作権者である作家3人がClaudeを開発するAnthropic社を提訴していたAI無断学習訴訟では、先日和解が成立したことも報じられています。これらの動きは、クリエイターの権利保護に向けた法廷闘争が現実的な成果を生み出し始めていることを示しています。
これらの動向は、GoogleやMicrosoft、OpenAIといった巨大テック企業ではなく、PerplexityやAnthropicのような新興AI企業を対象に訴訟が起こされるケースが多い傾向があるのは気になりますが、おそらく訴訟しやすい部分からの取り組みだと考えられ、今後巨大テック企業も視野に入れた法廷闘争へ発展していく可能性もあると予測されます。
※参照記事:日経・朝日、米AI検索パープレキシティを提訴 著作権侵害で(日本経済新聞)
※参照記事:読売新聞社、「記事無断利用」生成AI企業を提訴…日本の大手報道機関で初(読売新聞)
※参照記事:AI無断学習訴訟で和解 米アンソロピックと作家ら(時事通信ドットコム)
このような変化の中で、コンテンツの価値を正当に評価するPay Per Crawlが支持される土壌は確実に生まれつつあります。そして、Pay Per Crawlは、テキストだけでなく、画像、映像、音楽など、あらゆるコンテンツ分野において、生成AIの無断学習に対抗する技術の一つになり得ることも、クリエイターにとっては大きな希望になるでしょう。
こうした技術が普及するか否かは、私たちは見守ることしかできませんが、クリエイターの方々がPay Per Crawlという技術を正しく理解することは、その普及を後押しする大きな力となるでしょう。本記事が、その理解の一助になれば幸いです。

編集部おすすめ










































![[USBで録画や再生可能]Tinguポータブルテレビ テレビ小型 14.1インチ 高齢者向け 病院使用可能 大画面 大音量 簡単操作 車中泊 車載用バッグ付き 良い画質 HDMI端子搭載 録画機能 YouTube視聴可能 モバイルバッテリーに対応 AC電源・車載電源に対応 スタンド/吊り下げ/車載の3種類設置 リモコン付き 遠距離操作可能 タイムシフト機能付き 底部ボタン 軽量 (14.1インチ)](https://m.media-amazon.com/images/I/51-Yonm5vZL._SL500_.jpg)