
東京, 2025年9月8日 - (JCN Newswire) -当社は、AIサービス「Fujitsu Kozuchi」のコア技術として、大規模言語モデル(以下、LLM)の軽量化・省電力を実現するAI軽量化技術である生成AI再構成技術(以下、本技術)を開発し、当社のLLM「Takane」を強化することに成功しました。本技術は、AIの思考の基となる各ニューロン間の結合に割り当てられる重みを極限まで圧縮する世界最高精度の量子化技術(注1)と、軽量化と元のAIモデルを超える精度を両立させた世界初(注2)の特化型AI蒸留技術(注3)の2つのコア技術からなります。
本技術のうち量子化技術を「Takane」に適用することで、1ビット量子化(メモリ消費量最大94%削減)で、量子化前と比較して世界最高(注4)の精度維持率である89%と、量子化前の3倍の高速化を実現しました。量子化における従来の主流手法(GPTQ)(注5)の精度維持率は20%以下であり、それを大きく上回るものです。これにより、ハイエンドのGPU4枚を必要とする大型の生成AIモデルを、ローエンドのGPU1枚で高速に実行することが可能となりました。本技術による圧倒的な軽量化は、スマートフォンや工場の機械といったエッジデバイス上でのAIエージェントの実行を可能にします。これにより、リアルタイム応答性の向上とデータセキュリティの強化、そしてAI運用における抜本的な省電力化を実現し、サステナブルなAI社会に貢献します。当社は、量子化技術を適用した「Takane」のトライアル環境を2025年度下期(注6)より順次提供を開始します。さらにCohere社の研究用オープンウェイト「Command A」を本技術により量子化したモデルを、Hugging Face(注7)を通じて本日より順次公開します。当社は今後も、生成AIの能力を飛躍的に高めると同時に、その信頼性を保証する研究開発を推進することで、お客様や社会が直面するより困難な課題の解決に貢献し、生成AI活用の新たな可能性を切り拓いていきます。
背景
近年、生成AIは自律的にタスクを実行するAIエージェントへと進化し、その産業実装が急速に進む一方、基盤となるLLMは大規模化が進み、高性能なGPUを多数必要とすることから、開発・運用コストの増大や高い消費電力による環境負荷が大きな課題となっています。また、企業が生成AIを業務で本格的に活用するためには、汎用的なモデルをそのまま利用するのではなく、特定の業務に合わせて高精度化することや、工場や店舗などのエッジデバイスで利用するための軽量化が不可欠となっています。
生成AI再構成技術を構成する2つのコア技術
AIエージェントが実行するタスクの多くは、LLMが持つ汎用的な能力のごく一部しか必要としません。今回開発した生成AI再構成技術は、LLMの設計において、学習や経験、環境の変化に応じて神経回路を組み替え、特定のスキルに特化していく人間の脳の再構成の能力から着想を得ています。
汎用的な知識を持つ巨大なモデルから、特定の業務に必要な知識だけを効率的に抽出し、軽量・高効率で信頼性の高い専門家の脳のように特化したAIモデルを創出します。これを実現するのが、本技術の以下の2つのコア技術です。
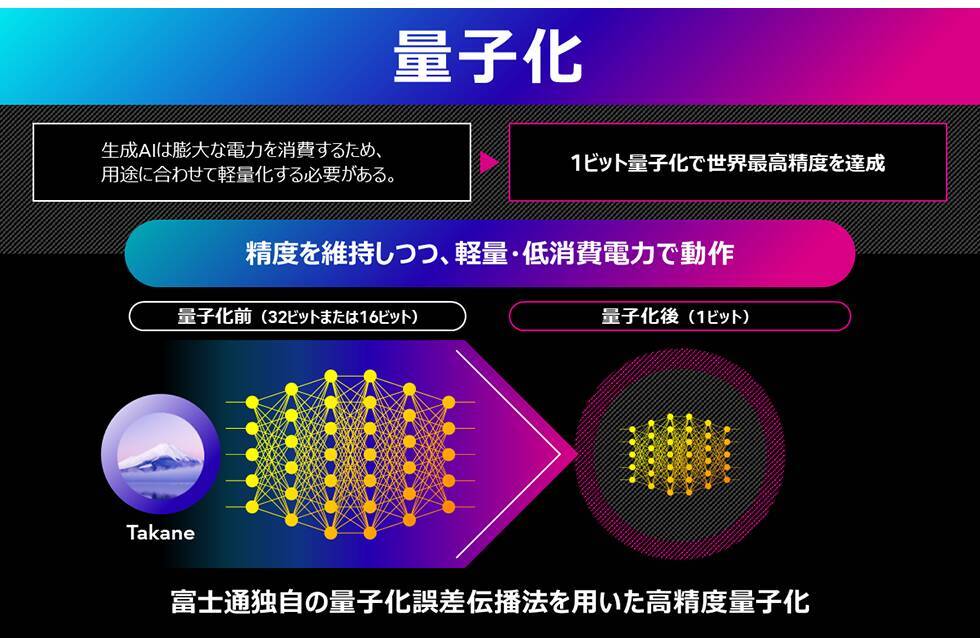
1.AIの思考を効率化し、消費電力を削減する量子化技術
本技術は、生成AIの思考の基となる膨大なパラメータの情報を圧縮し、大幅に生成AIモデルの軽量化・省電力化と高速化を実現します。従来手法では、LLMのような層が多いニューラルネットワークにおいて、量子化誤差が指数関数的に蓄積することが課題でした。そこで、当社は理論的洞察に基づき、層をまたいで量子化誤差を伝播させることで増大を防ぐ新たな量子化アルゴリズム(QEP:Quantization Error Propagation)を開発しました。さらに、当社が開発した大規模問題向けの世界最高精度の最適化アルゴリズムであるQQA(注8)を活用することで、LLMの1ビット量子化を実現しました。
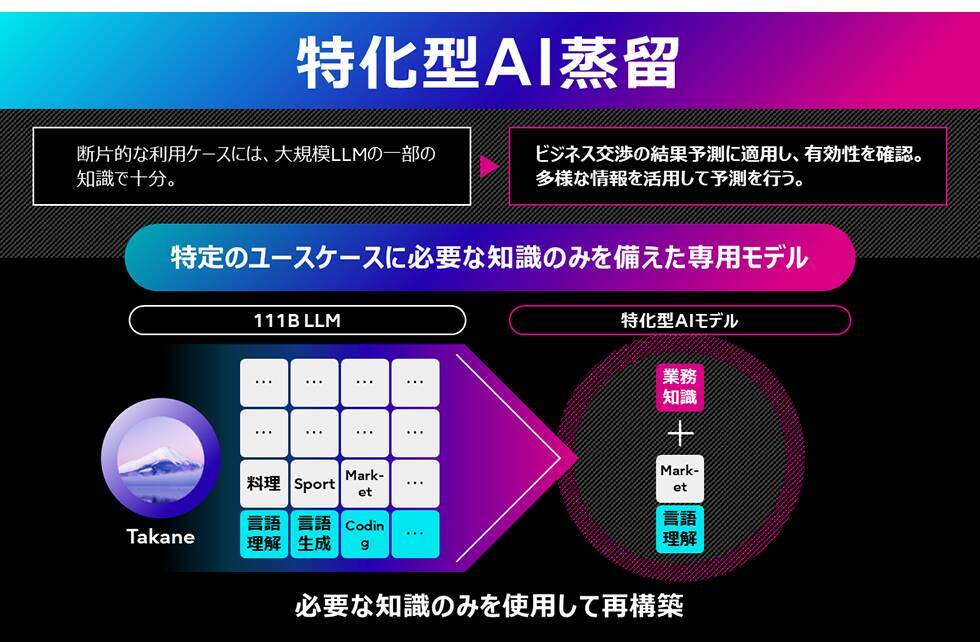
2.専門知識を凝縮し、精度を向上させる特化型AI蒸留技術
本技術は、脳が必要な知識を強化し、不要な記憶を整理するように、AIモデルの構造を最適化します。まず基盤となるAIモデルに対し、不要な知識を削ぎ落とすPruning(枝刈り)や、新たな能力を付与するTransformerブロックの追加などを行い、多様な構造を持つモデル候補群を生成します。次に、これらの候補の中から、当社独自のProxy(代理評価)技術を用いたNeural Architecture Search(NAS)により、顧客の要望(GPUリソース、速度)と精度のバランスが取れた最適なモデルを自動で選定します。最後に、選定された構造を持つモデルに、「Takane」などの教師モデルから知識を蒸留します。この独自のアプローチにより、単なる圧縮に留まらず、特化したタスクでは基盤の生成AIモデルを上回る精度を達成します。
当社のCRM(顧客関係管理)データを用いて各商談の勝敗を予測するテキストQAタスクの実証では、本技術により過去データに基づくタスクに特化した知識のみを蒸留したモデルを用いることで、推論速度を11倍に高速化しつつ、精度を43%改善するなど、大幅な精度向上を確認しました。
高精度化とモデル圧縮を同時に実現することで、教師モデルを超える精度を、より軽量な100分の1のパラメータサイズの生徒モデルで達成できることを確認しており、必要なGPUメモリと運用コストをそれぞれ70%削減すると同時に、より信頼性の高い商談勝敗予測が可能となりました。また、画像認識タスクにおいては、未学習の物体に対する検出精度を、既存の蒸留技術と比較して10%向上させることに成功しました(注9)。これは、同分野における過去2年間の精度向上幅の3倍以上に相当する飛躍的な成果です。
今後について
当社は、本技術を適用することで「Takane」の進化を加速させ、お客様のビジネス変革を強力に支援します。今後は、今回の成果を基に、金融、製造、医療、小売など、より専門性の高い業務に特化した「Takane」から生まれる軽量AIエージェント群を開発・提供していきます。また当社は、本技術をさらに発展させ、生成AIの精度を維持したままモデルのメモリ消費量を最大1,000分の1へ削減し、あらゆる場所で高精度かつ高速な生成AIが利用できる世界の実現に貢献していきます。さらに将来的には、これらの特化型「Takane」を進化させて、世界の仕組みや因果関係をより深く理解し、複雑な課題に対して自律的に最適な解決策を導き出すAIエージェント向けの生成AIアーキテクチャに発展させていきます。
URL https://global.fujitsu/ja-jp/pr/news/2025/09/08-01
Copyright 2025 JCN Newswire. All rights reserved. www.jcnnewswire.com
編集部おすすめ













![「キューズQ」限定カラー版フィギュアなど『ワンダーフェスティバル 2026[冬]』限定販売商品の事後通販を、「あみあみ」にてご案内中。](http://imgc.eximg.jp/i=https%253A%252F%252Fs.eximg.jp%252Fexnews%252Ffeed%252FPrtimes%252Ff8%252FPrtimes_2026-02-09-25615-3271%252FPrtimes_2026-02-09-25615-3271_1.jpg,zoom=184x184,quality=100,type=jpg)















