アップルも注目する小型LLM
ChatGPT、特にGPT-4が登場して以来、大規模言語モデル(LLM)の性能向上において、パラメータ数を増やすアプローチが主流となってきた。しかし最近では、パフォーマンスを維持しつつ、パラメータ数を減らす、小型モデルの開発が活発化している。この大規模言語モデルの小型化において、水面下で動いているのがアップルだ。アップルは2023年12月、「LLM in a flash」という論文を発表。この研究では、iPhoneやMacBookといったメモリ制約のあるデバイスでLLMを動作させる手法が提案されている。具体的には、モデルの一部をDRAMに、残りをフラッシュメモリに分散して格納し、必要に応じてDRAMとフラッシュメモリ間でモデルの重みを動的に入れ替えるというアプローチ。これにより、メモリ使用量を大幅に減らしつつ、推論の遅延を最小限に抑えることができるという。特にApple Silicon上で動作させた場合、高いパフォーマンスを発揮すると報告されている。
さらにアップルは、「LLM in a flash」に先立ち、推論の計算量を最大3倍削減できるLLMアーキテクチャに関する論文も公開していた。
オフラインでも高速かつ高品質のパフォーマンスを発揮するAI、これがアップルの生成AI戦略の要になっているようだ。
H2Oがリリースした小型LLM「Danube」とは?
アップルと同様に、小型LLMの開発に注力しているのがAIの民主化を掲げるH2O AIだ。2024年2月29日、同社はスマホやラップトップなどモバイルデバイス向けの大規模言語モデル「Danube 1.8B」をリリースしたことを発表した。H2O AI(2012年創業、シリコンバレー拠点)は、Apache 2.0ライセンスのもとで、幅広いオープンソースおよびライセンスツールを提供し、AIの民主化を目指す企業だ。欧州第2位の河川「ドナウ」に因んで名付けられたDanube 1.8Bは、18億のパラメータを持ち、同規模のモデルと同等、あるいはそれを上回る性能を発揮したとされている。
H2Oのスリ・アンバティCEOによれば、Danube 1.8Bは「スマートフォンなどの小型デバイスで利用できるポータブルなLLM」だ。特にモバイル・オフラインアプリケーション向けに設計されており、小型かつ低コストのモバイルデバイスの普及に伴い、Danube 1.8Bのような小型LLMの需要も高まることが予想されるという。
大手企業においては、モバイルデバイス上でローカルに動作し、迅速な応答を生成する生成AIの可能性を探る動きが活発化しているといわれており、H2Oのような小型モデルへの関心が高まりつつある状況でもある。
Danube 1.8Bは、推論、読解、要約、翻訳など、モバイルデバイス上のさまざまな自然言語アプリケーション向けにファインチューニングできるとのこと。たとえば、翻訳機能に特化したファインチューニングを行うことで、オフラインで利用できる高品質の翻訳アプリケーションの構築が可能となる。
ベンチマークテストでは、1~20億パラメータのカテゴリにあるほとんどのAIモデルと同等以上の性能を示しており、期待値は高い。たとえば、常識的な自然言語推論を評価するHellaswagテストでは、69.58%の精度を発揮。これはStability AIの16億パラメータモデル「Stable LM 2」に次ぐ高い数値だ。
H2Oは、Danubeを商用利用可能なApache 2.0ライセンスで公開しており、モバイルユースケースへの実装を検討するユーザーは、Hugging Faceからダウンロードしてアプリケーション固有のファインチューニングを行うことができる。H2Oはまた、このプロセスをより簡単にするための追加ツールの提供も計画している。さらに、チャットアプリケーション向けに、Danubeのチャットチューニング版「H2O-Danube-1.8B-Chat」もリリースしており、チャットアプリケーションへの応用も可能となっている。
Danubeのような小型LLMは増加傾向にあり、スマートフォンなどのモバイルデバイス上で稼働するオフライン生成AIアプリケーションの急増が予想されるところだ。要約、スマートタイピング、翻訳のほか学習のパーソナライゼーション、画像編集など、さまざまな用途が想定される。
Danubeと他モデルの比較
Danubeのテクニカルレポートによると、モデルは主にウェブドキュメントや百科事典、公共のナレッジデータベースなど、合計1兆トークンのデータセットを用いて学習された。コーディングはモデル開発の範疇ではないため、コーディングデータは除外されている。
学習には、処理効率を高めるLlama 2やMistralのコア原理を採用。具体的には、Mistralから採用したローカルアテンションのためのスライディングウィンドウ、Rotary Positional Embedding(RoPE)、クエリをグループ化するGrouped-query attentionなどの技術が活用されている。どれも計算効率を高める手法であり、スマートフォンなどの制約があるモバイルデバイス上での活用を考えた場合、非常に重要な要素となる。
たとえば、スライディングウィンドウ。一般的な言語モデルは、文章を処理する際に、文章全体を一度に見るというアプローチをとっている。
これは、精度が高まるという利点がある一方で、効率は非常に悪く、制約が多いモバイルデバイスには不向き。ここで、スライディングウィンドウという手法を使うことで、一度にすべての文章を処理するのではなく、「小さな窓」を通じて文章を処理、それをスライドしていくことで、効率性を大きく高めることが可能となるのだ。
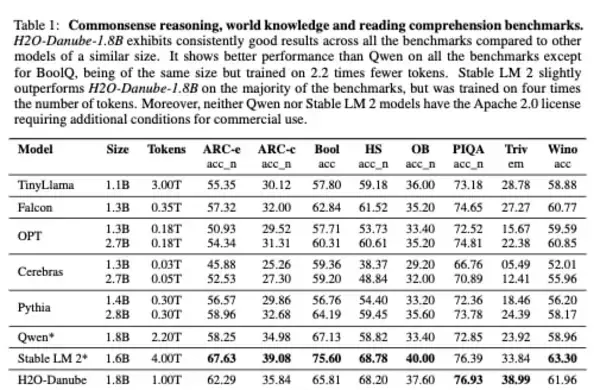
Danubeモデルの性能は、常識的な推論、世界知識、読解など幅広いジャンルのベンチマークで評価された。その結果、Danube 1.8Bは同規模の他モデルと比較しても、優れたパフォーマンスを発揮することが確認された。最も近い競合モデルはQwenとStable LM 2だ。
常識的な推論・世界知識・読解力に関して、Danube 1.8BはBoolQを除くすべてのベンチマークでQwenよりも優れた性能を示した。
Qwenモデルは同じ18億のパラメータを持ちながら、Danubeの2.2倍にあたる2兆2,000億トークンで学習されている。一方、Stable LM 2は大半のベンチマークでDanube 1.8Bをわずかに上回ったが、Stable LM 2はDanubeの4倍にあたる4兆トークンで学習されている。つまり、Danubeは1トークンあたりの情報をより効率的に抽出・活用できたと考えられる。
常識的な推論・世界知識・読解力に関するベンチマーク
(Danubeのテクニカルレポートより)
また、QwenもStable LM 2もApache 2.0ライセンスではなく、商用利用には追加の条件が必要となる点も留意すべきだろう。
サイズが小さいことから、Danube 1.8BはGPUを搭載していないラップトップのローカル環境でも利用することができ、ネット接続を常時確保するのが困難な人にも朗報となる可能性がある。
DanubeのようなLLMの登場により、オフラインでも高度な自然言語タスクを処理できるアプリケーションの登場が期待される。大規模言語モデル開発において各社は、小型化を推進しつつ、どこまで性能を高めることができるのか、アップルの小型LLMの開発動向を含め、今後の動きにも注目が集まる。
文:細谷元(Livit)





















![[医食同源ドットコム] iSDG 立体型スパンレース不織布カラーマスク SPUN MASK 個包装 ホワイト 30枚入](https://m.media-amazon.com/images/I/51m0nKLQ+rL._SL500_.jpg)
![[医食同源ドットコム] iSDG KUCHIRAKU MASK (クチラクマスク) ホワイト 30枚入 ダイヤモンド型 くちばし型 メイクが付きにくい](https://m.media-amazon.com/images/I/51S5YMnLMNL._SL500_.jpg)
![[医食同源ドットコム] iSDG 不織布マスクPREMIUM 50枚入り (個包装) (ふつう)](https://m.media-amazon.com/images/I/51XlQaY1QuL._SL500_.jpg)








